-
Research Statement
The stunning ability to communicate abstract messages is a quintessential human trait that uniquely defines us in the animal kingdom. At the same time, human language is a complex behavior that presumably draws in large parts on evolutionarily younger neural/cognitive systems. Research in the Human Language Processing (HLP) Lab seeks to understand the computational cognitive systems that allow the human brain to communicate information at a rate and complexity that far exceeds that of other animals.
Read more »
-

T. Florian Jaeger and Katrina Housel Furth during fieldwork in the Yucatan in 2009 -
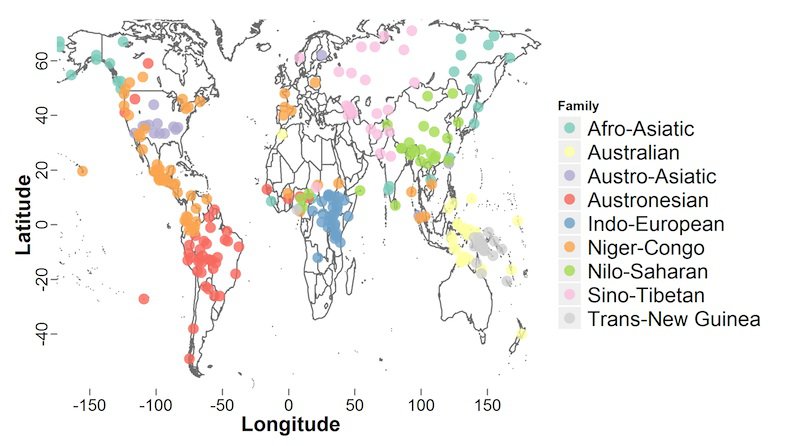
Typological analysis -
Robust language understanding in a variable world -
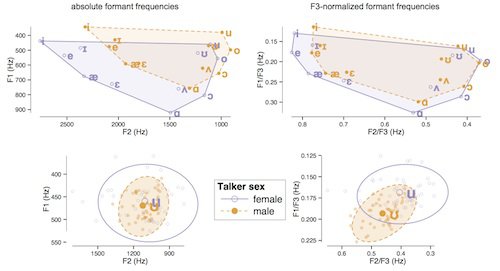
Speech Perception -
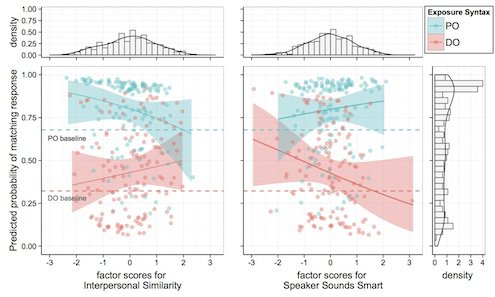
Alignment
06 December 2018: Jiří Zámečník (Graduate Student, English, Albert-Ludwigs-Universität Freiburg) UID in Early Modern English
[Detail]29 November 2018: Grace Wenling Cao (Graduate Student, Linguistics, University of York) Phonetic convergence of Hong Kong English towards native English accents and the effect of language attitudes
[Detail]15 November 2018: Guillermo Montero Melis (Postdoc, Centre for Research on Bilingualism, Stockholm University) Wanna replicate embodiment effects? Do you have the power?
[Detail]30 October 2018: Timo Roettger (Postdoctoral researcher, Linguistics, Northwestern University) Prediction and adaptation in prosodic processing
[Detail]12 April 2017: Rachel Tatman (PhD student, Department of Linguistics, University of Washington) Skype talk
[Detail]28 February 2017: Andrés Buxó-Lugo (PhD student, Department of Cognitive Psychology, University of Illinois at Urbana-Champaign) Expectations and adaptation in prosodic processing
[Detail]23 February 2017: Eleanor Chodroff (PhD student, Department of Cognitive Sciences, Johns Hopkins University) Uniformity in talker-specific phonetic realization: Evidence from sibilant fricatives in American English and Czech
[Detail]14 February 2017: Rachel Smith (Senior Lecturer, English Language and Linguistics, University of Glasgow) Skype talk
[Detail]02 February 2017: Amelia Kimball (PhD student, Department of Linguistics, University of Illinois at Urbana Champaign) Categorical vs. Episodic Memory for Pitch Accents in American English
[Detail]23 January 2017: Bruno Nicenboim (PhD student, Department of Linguistics, University of Potsdam, Germany) Models of retrieval in sentence comprehension: A computational evaluation using Bayesian hierarchical modeling
[Detail]03 November 2016: Laura Gwilliams (PhD student, Cognition and Perception Doctoral Program, New York University) In spoken word recognition, the future predicts the past.
[Detail]16 May 2016: Kuniko Nielsen (Assoiciate Professor, Linguistics, Oakland University) Skype talk
[Detail]